Infectious Diseases
Category: Abstract Submission
Infectious Diseases: MIS-C & Kawasaki Disease

Arthur Chang, MD
Fellow
John R. Oishei Children's Hospital
SUNY The State University of New York
buffalo, New York, United States
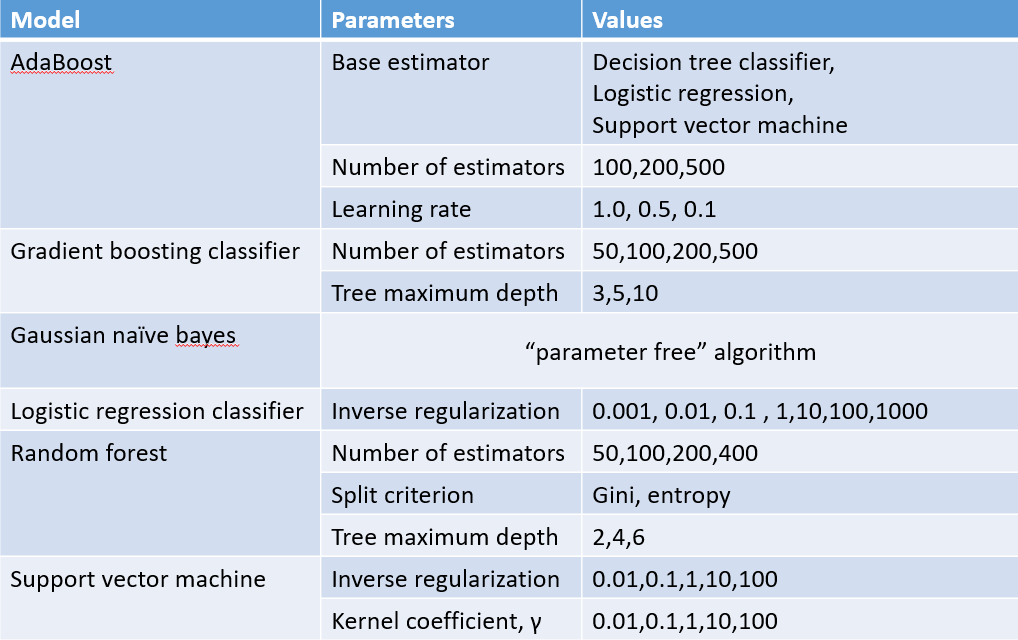
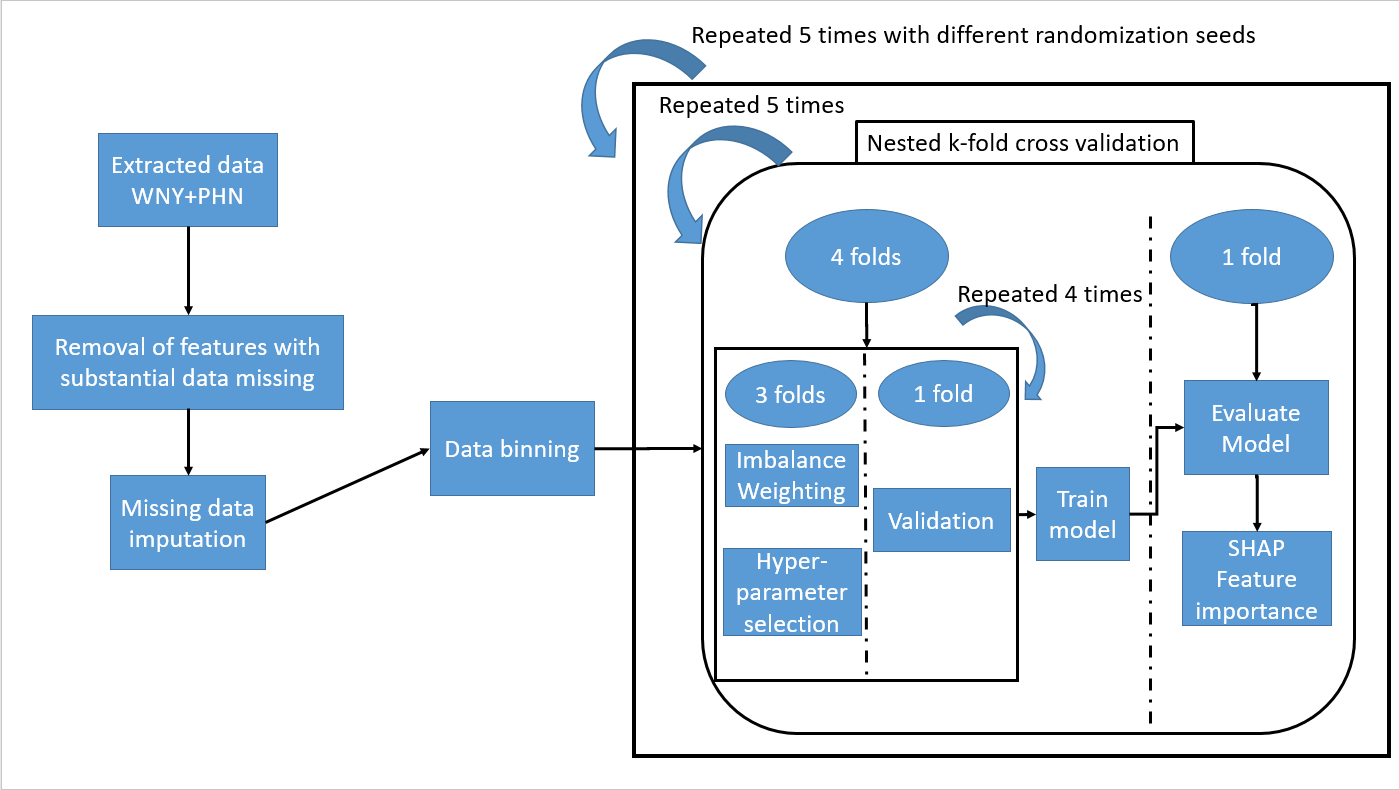 Data from our region (WNY) and extracted data from the Pediatric Heart Network study on Kawasaki Disease (PHN) were processed and binned before training with a nested k-fold cross validation strategy using both conventional class weighting and synthetic data weighting. The process was repeated a total of 5 times with different seeds to ensure results were replicable.
Data from our region (WNY) and extracted data from the Pediatric Heart Network study on Kawasaki Disease (PHN) were processed and binned before training with a nested k-fold cross validation strategy using both conventional class weighting and synthetic data weighting. The process was repeated a total of 5 times with different seeds to ensure results were replicable.